Readme¶
_ _ _ _ _ _ _
| | | (_) | | (_) |
| |__ __ _ _ __ __| |_| |_ _ __ _ _| |_| |__
| '_ / _` | '_ / _` | | __| '_ \| | | | | | '_
| |_) | (_| | | | | (_| | | |_| |_) | |_| | | | |_) |
|_.__/ \__,_|_| |_|\__,_|_|\__| .__/ \__, |_|_|_.__/
| | __/ |
|_| |___/
A lightweight python library for bandit algorithms
Introduction¶
This library is intended to enable fast and robust comparison between different bandit algorithms. It provides following features:
object-oriented design: this allows unnecessary environmental information to be hidden from learners. Besides, it is easy extend the library and implement new algorithms.
multi-process support: it is not uncommon to run a game muitiple repetitions. One can run multiple repetitions simultaneously with this feature.
friendly runtime information: useful information is provided when necessary, which reduces the difficulty of debug.
The library consists of four submodules and they are arms, bandits, learners and protocols respectively, among which protocols are those used to coordinate the interactions between the learner and the bandit environment.
Implemented Policies¶
Single player protocol¶
Multi-armed bandit¶
Goal |
Policies |
|---|---|
Maximize total rewards |
|
Best arm identification with fixed budget |
|
Best arm identification with fixed confidence |
|
MNL bandit¶
Goal |
Policies |
|---|---|
Maximize total rewards |
|
Thresholding bandit¶
Goal |
Policies |
|---|---|
Make all answers correct |
|
Linear bandit¶
Goal |
Policies |
|---|---|
Maximize total rewards |
|
Colaborative learning protocol¶
Multi-armed bandit¶
Goal |
Policies |
|---|---|
Best arm identification with fixed time |
|
For a detailed description, please check the documentation.
Getting Started¶
Installing¶
Python version requirement: 3.7 or above.
Virtual environment: in order not to pollute your own environment, it is suggested to use python virtual environment. The following commands show the details to create and activate a virtual environment.
# Create a virtual environment `.env`
python3 -m venv .env
# Activate the environment
source .env/bin/activate
Then you can run the following command to install the banditpylib library.
make install
After finishing the usage of the library, you can use deactivate to deactive the virtual environment and what’s more, you can safely delete the whole .env directory for cleanup.
The following shows other useful make commands.
make test
run tests
make lint
run pylint and mypy
make clean
clean cache files
make fix
run yapf to format all .py files
make all
run make fix, make test, and make lint
We use pylint and mypy to check the code style. Please make sure no errors occur with make all when submitting a PR.
Example¶
Suppose we want to run algorithms Epsilon Greedy, UCB and Thompson Sampling, which aim to maximize the total rewards, against the ordinary multi-armed bandit environment with 3 Bernoulli arms. The following code blocks show the main logic.
Set up bandit environment¶
# Real means of Bernoulli arms
means = [0.3, 0.5, 0.7]
# Create Bernoulli arms
arms = [BernoulliArm(mean) for mean in means]
# Create an ordinary multi-armed bandit environment
bandit = MultiArmedBandit(arms=arms)
Set up learners¶
# Create learners aiming to maximize the total rewards
learners = [EpsGreedy(arm_num=len(arms)),
UCB(arm_num=len(arms)),
ThompsonSampling(arm_num=len(arms))]
Set up simulator and play the game¶
# Horizon of the game
horizon = 2000
# Set up simulator using single-player protocol
game = SinglePlayerProtocol(bandit=bandit, learners=learners)
# Record intermediate regrets after these horizons
intermediate_horizons = list(range(0, horizon+1, 50))
# Start playing the game and for each setup we run 200 trials
game.play(trials=200,
intermediate_horizons=intermediate_horizons,
horizon=horizon)
The following figure shows the simulation results.
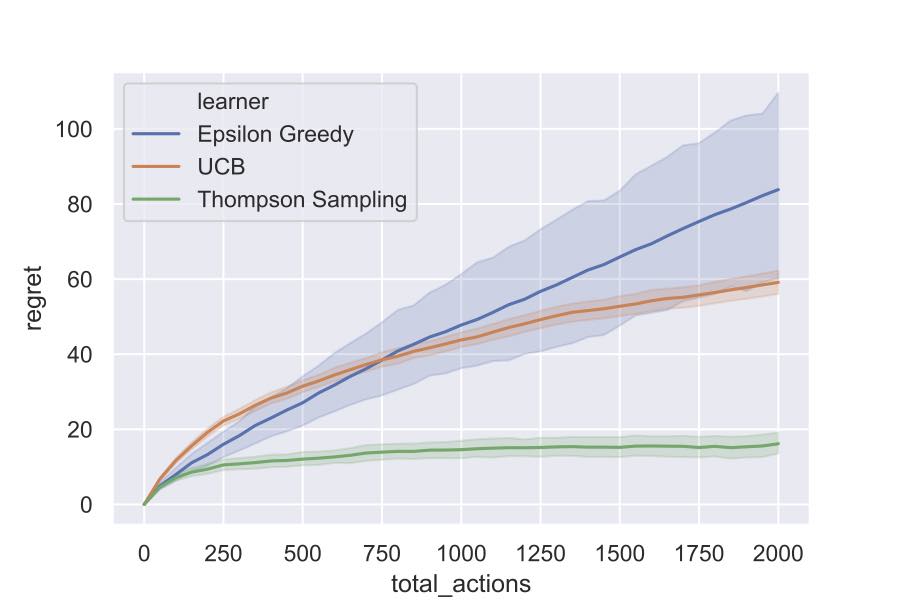
Please check this notebook to figure out more details.
Bibtex Citation¶
@misc{BanditPyLib,
title = {{BanditPyLib: a lightweight python library for bandit algorithms}},
author = {Chester Holtz and Chao Tao and Guangyu Xi},
year = {2020},
url = {https://github.com/Alanthink/banditpylib},
howpublished = {Online at: \url{https://github.com/Alanthink/banditpylib}},
note = {Documentation at \url{https://alanthink.github.io/banditpylib-doc}}
}
License¶
This project is licensed under the MIT License - see the LICENSE.txt file for details.
Acknowledgments¶
This project is inspired by libbandit and banditlib which are both c++ libraries for bandit algorithms.
This readme file is following the style of README-Template.md.
The title is generated by TAAG.